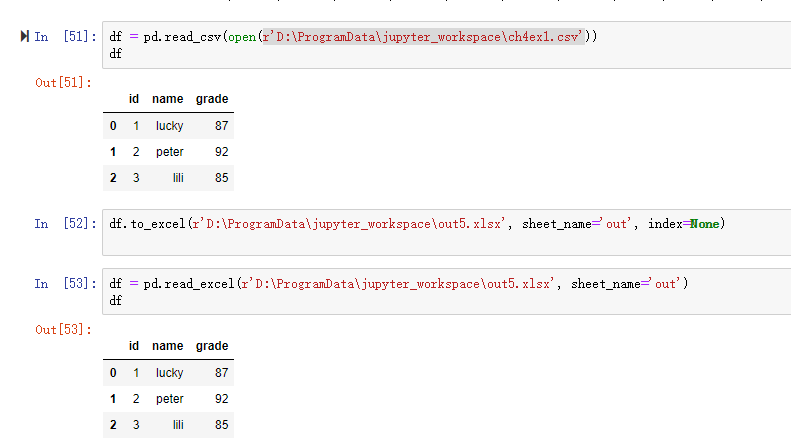
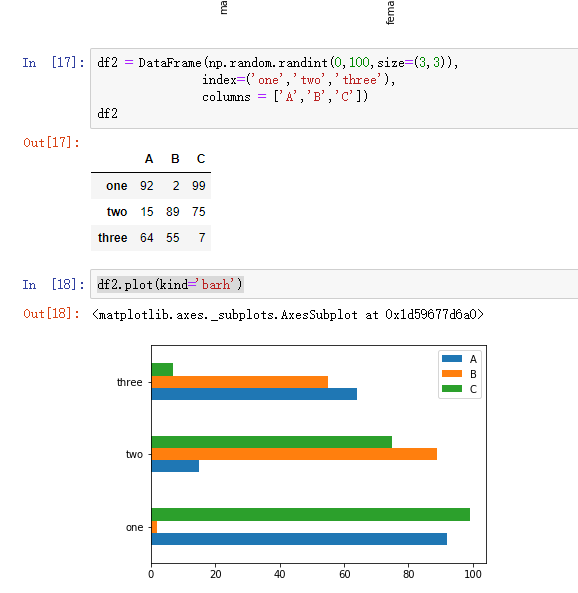
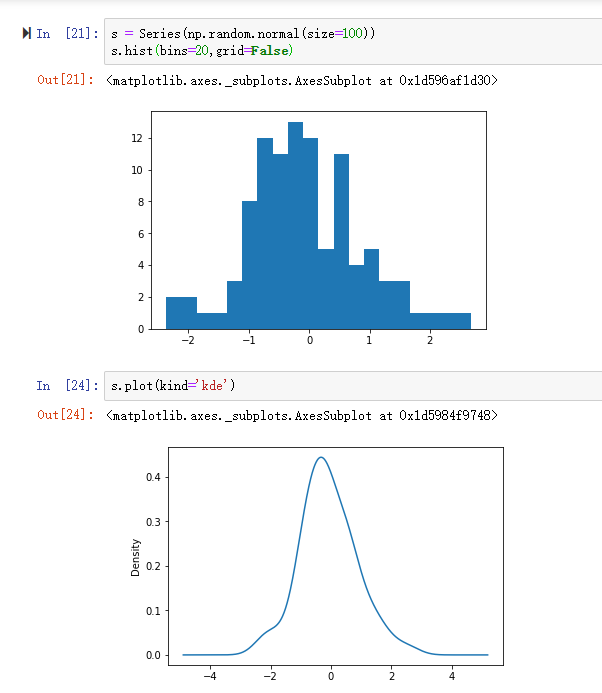
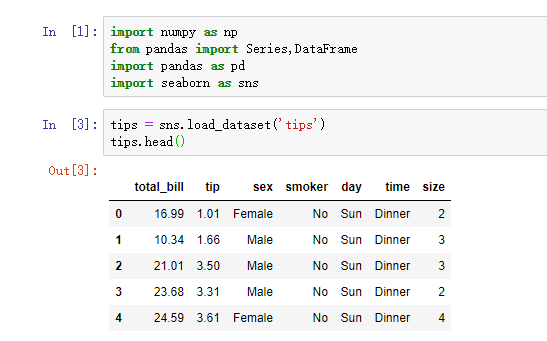
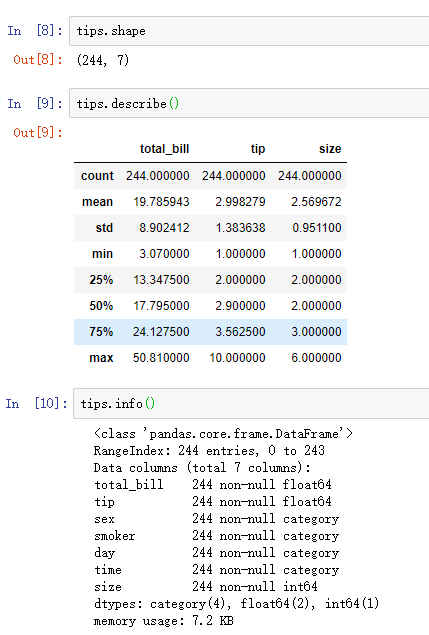
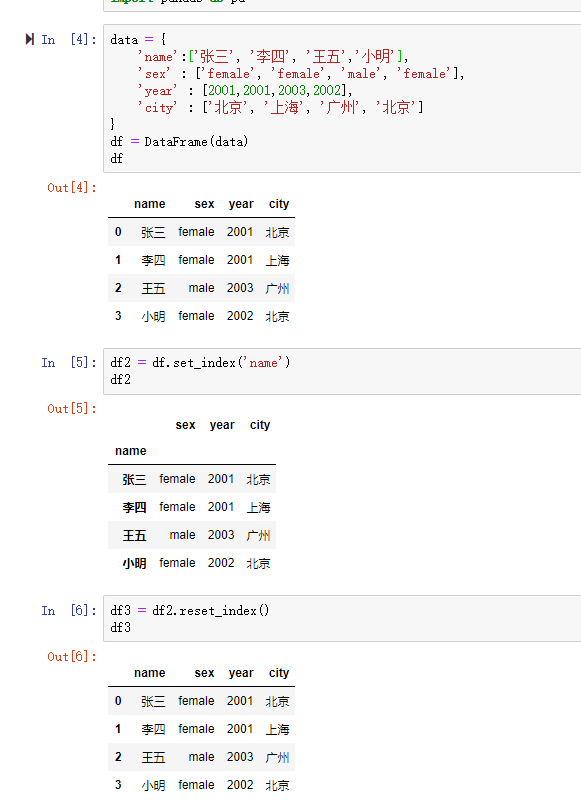
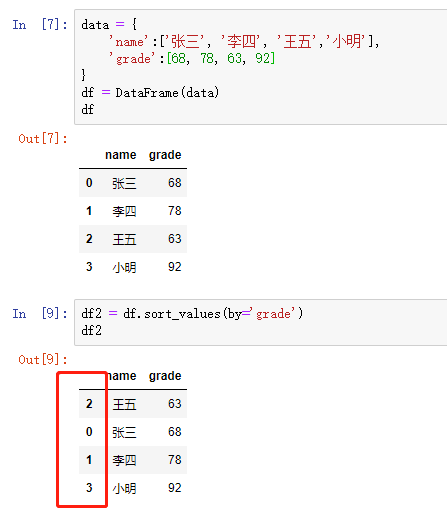
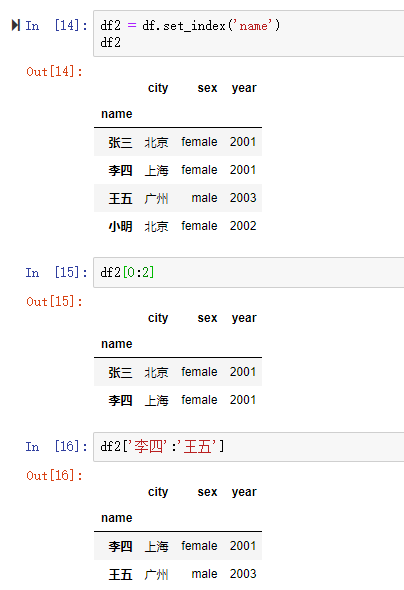
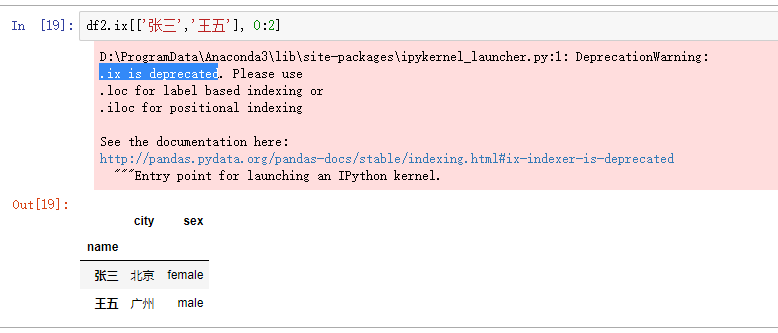
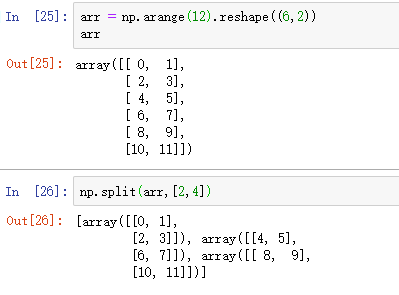
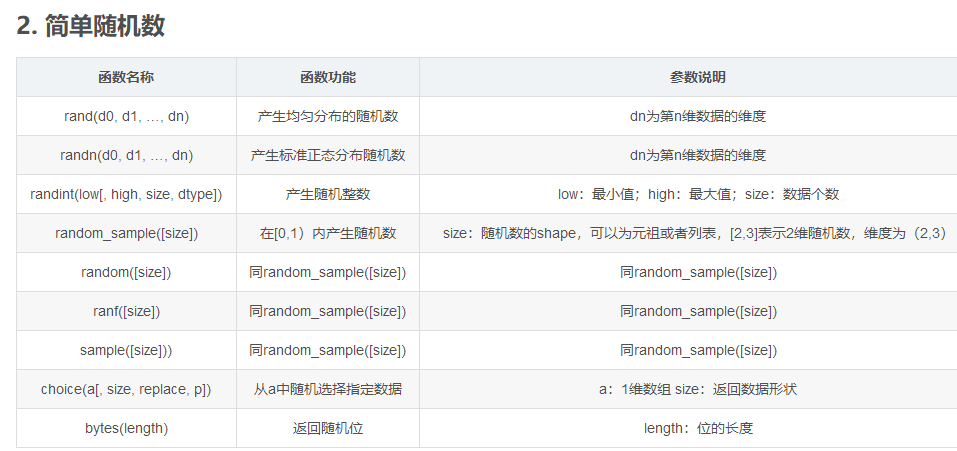
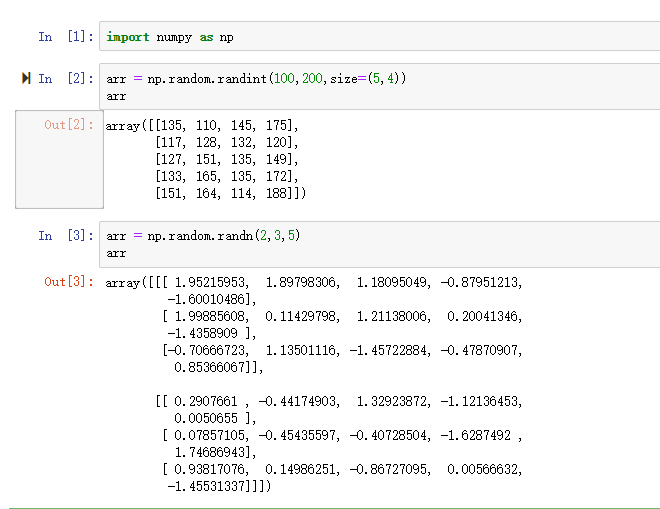
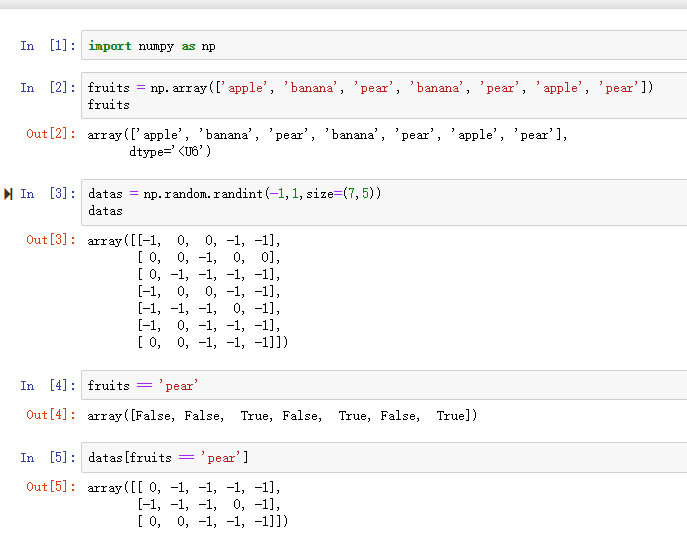
一、数据库的读取与存储
(一) MySQL8.0安装
1. mysql8.0 msi安装教程
https://blog.csdn.net/qq_42773146/article/details/82414057
安装包版本的参考上述文章
2.MySQL-mysql 8.0.11安装教程
http://www.cnblogs.com/laumians-notes/p/9069498.html
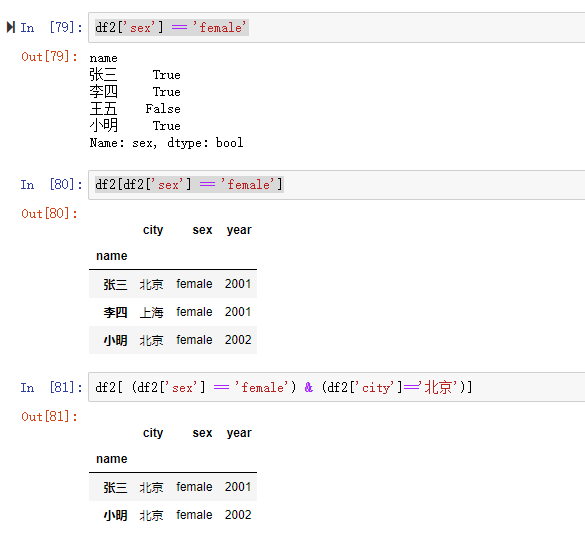
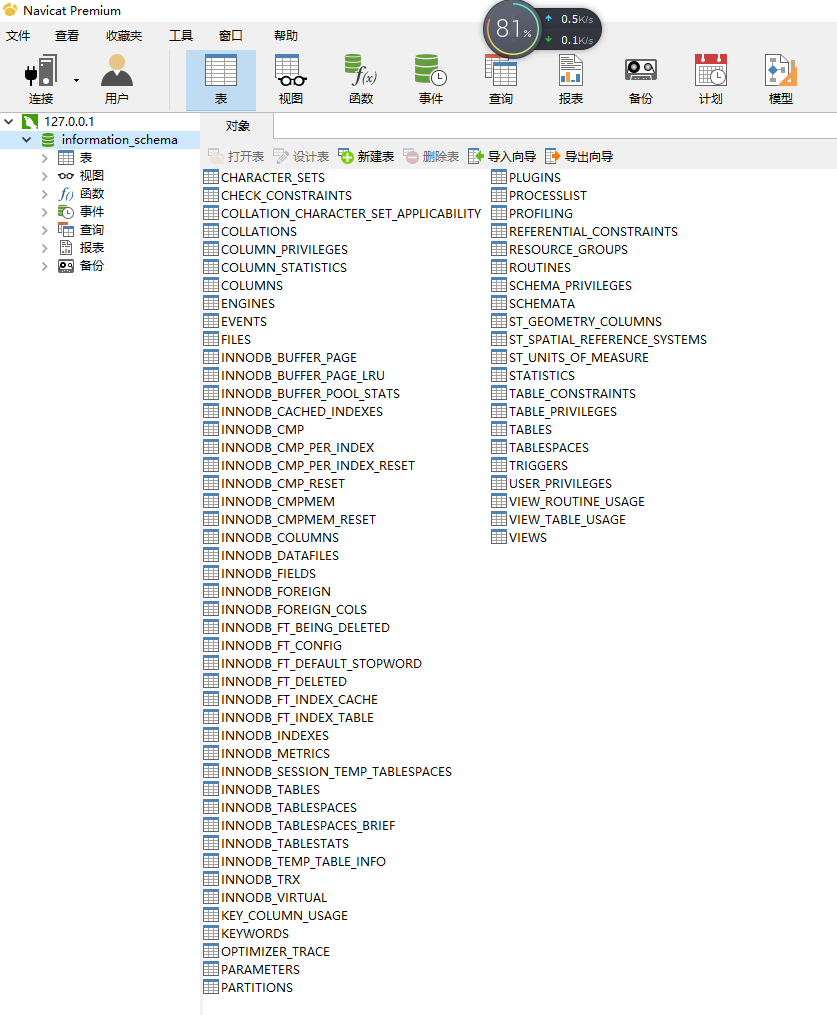
按照上面教程一步步下来即可成功安装,通过Navicat连接如下
(二) 连接数据库
1. 安装pymysql


2. 读取数据库
(1) 通过PyMySQL -> DataFrame
先通过PyMySQL读取数据,得到元组列表,再传给DataFrame构造器

(2) 直接通过read_sql

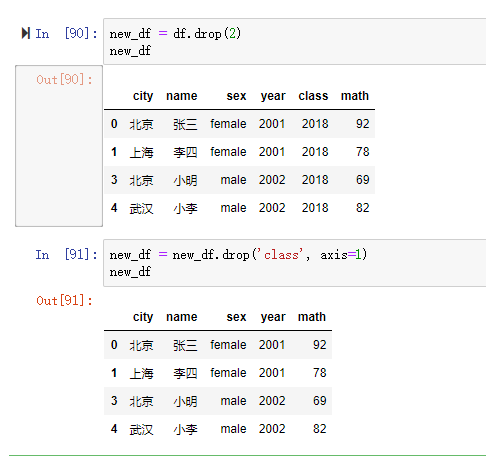
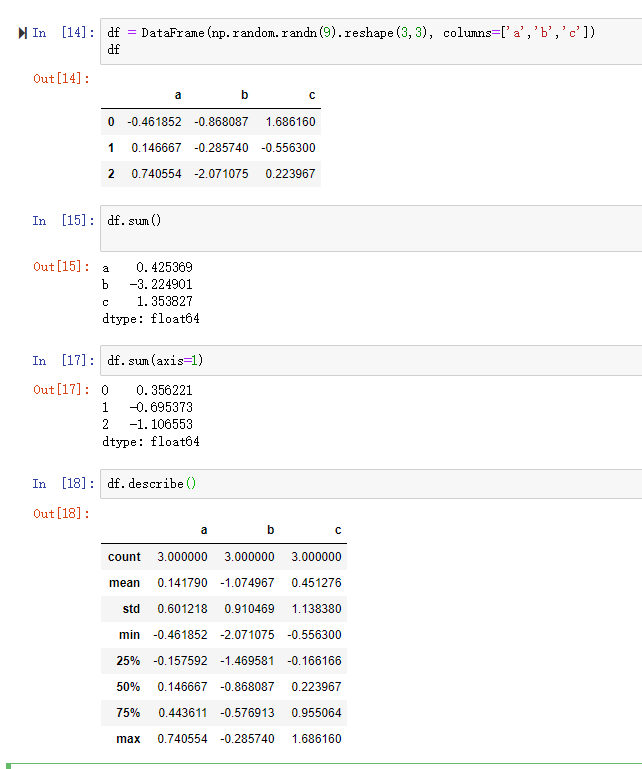
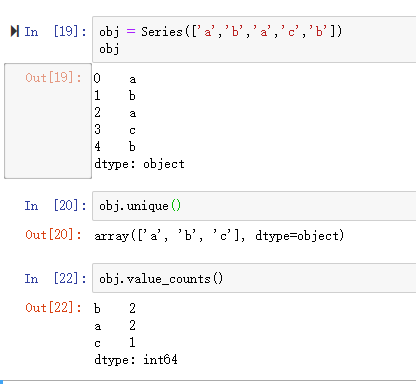
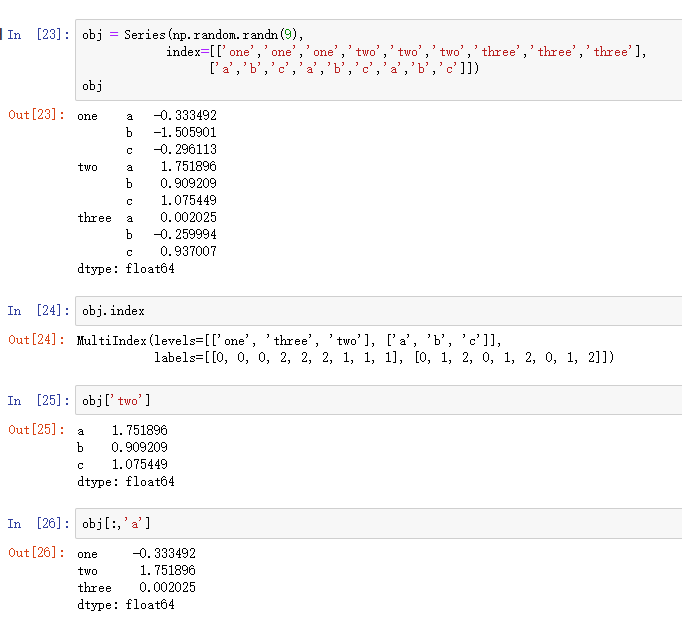
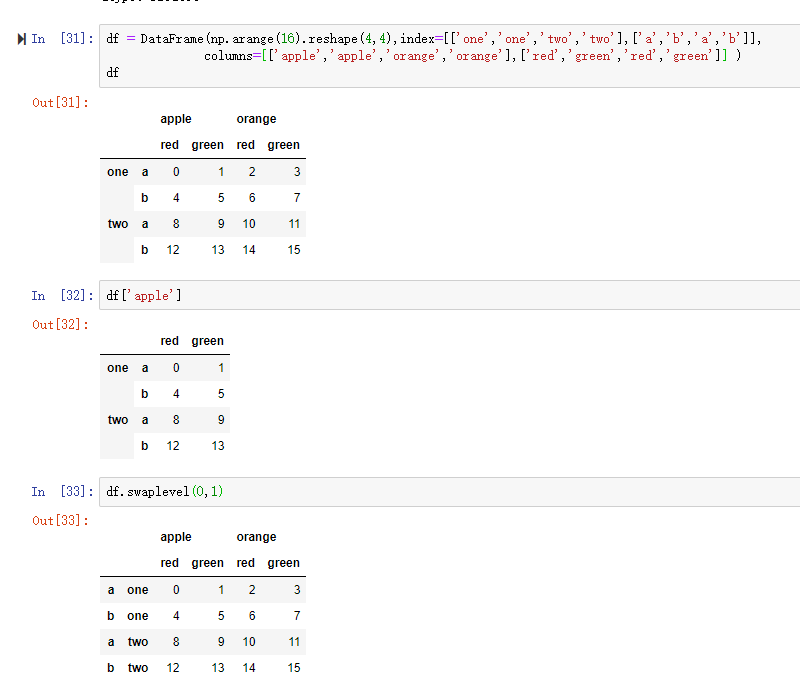
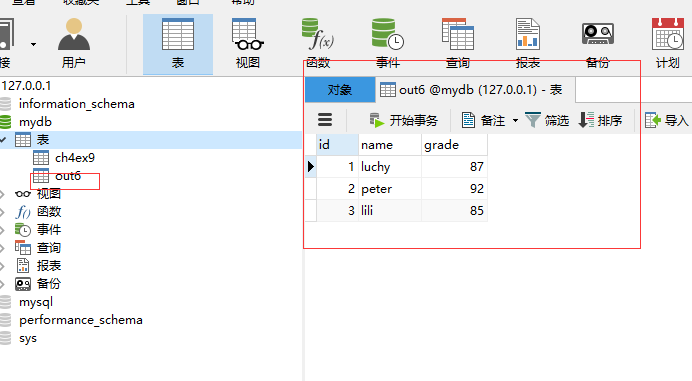
3. 存储数据库
通过to_sql函数实现DataFrame数据存储为MySQL数据,首先查看to_sql参数
df.to_sql(name, con, flavor=None, schema=None, if_exists=’fail’, index=True, index_label=None, chunksize=None, dtype = None)
其中
name参数存储的表名
con为连接的数据库
if_exists参数用于判断是否有重复表名,其中fail表示如果有重复表名,就不存;replace表示替换重复表名;append表示在该表中继续插入数据。
新版pandas中,con参数不能使用pymysql连接数据库

二、Web数据的读取
(一) 读取Html表格
利用pandas库中的read_html方法快速抓取网页中常见的表格型数据
http://www.cnblogs.com/sanduzxcvbnm/p/10250222.html

(二) 网络爬虫
并非所有的网页数据存在HTML表格中,这就需要通过网络爬虫获取所有数据。
以酷狗榜单中TOP500的音乐信息为例
http://www.kugou.com/yy/rank/home/1-8888.html




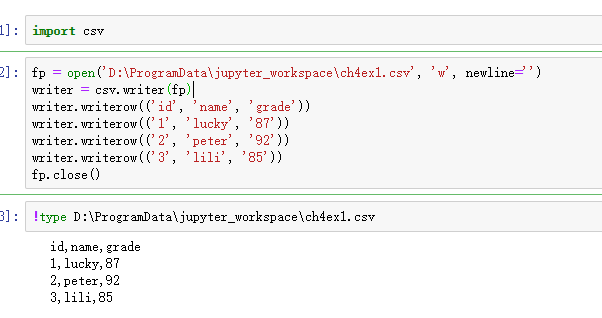
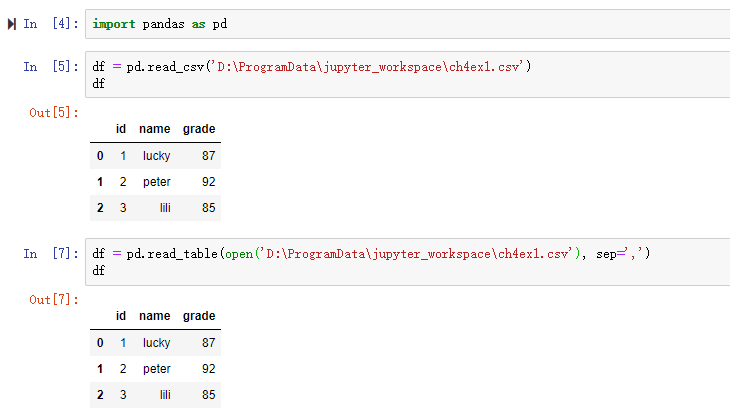
 ‘’
‘’